Run name for each run - this is useful to keep track between many different runs.
Running against a base LLM
If you want to run a test suite against a stock model (e.g. base gpt-4o), you can do so by clicking theStart Run button on the upper-right
of the test-suite page.
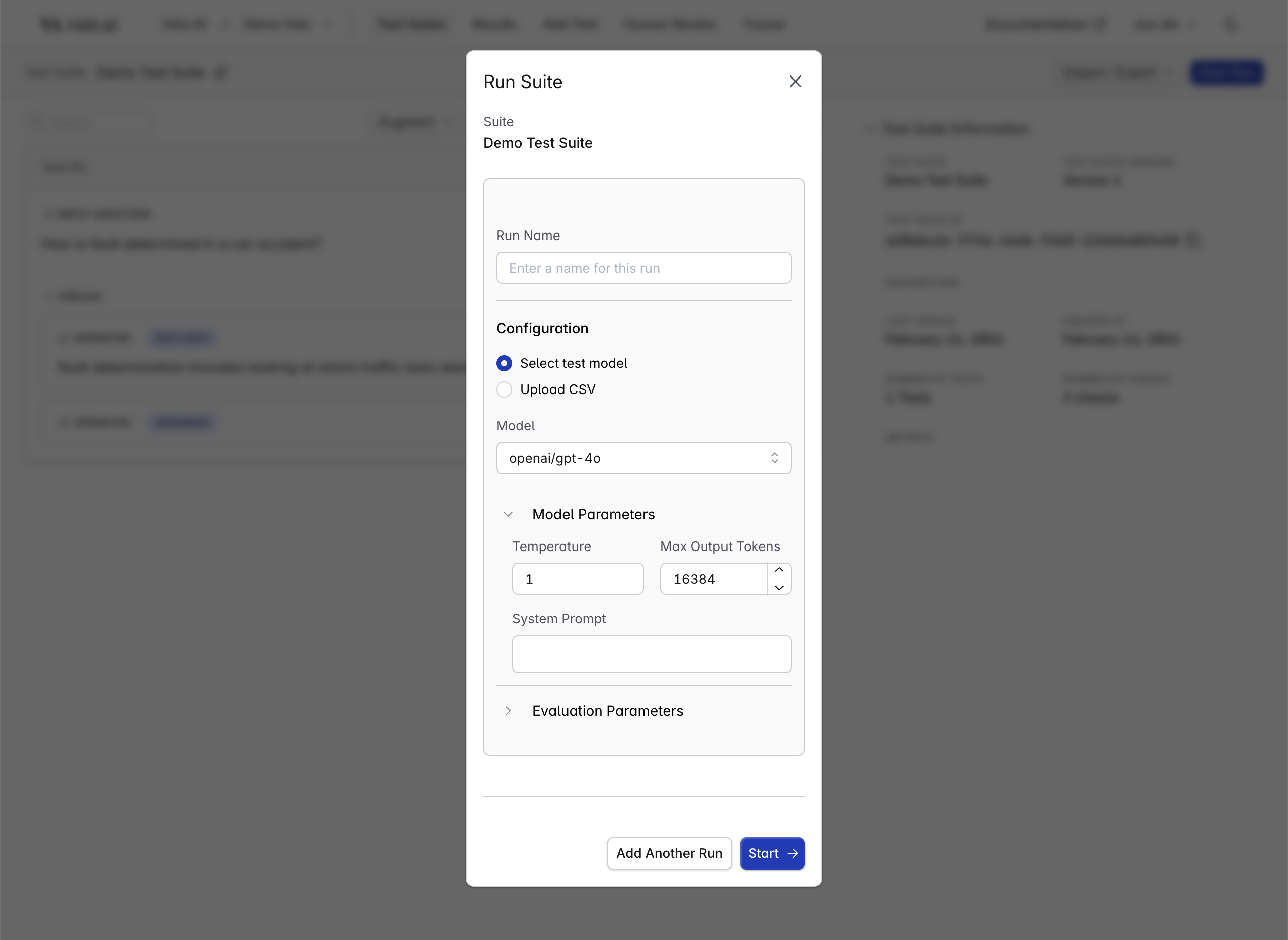
Note: By default, we only make a subset of models available to users. If you’re interested in using additional models, including those hosted on Bedrock and Azure, please reach out to the Vals team.Model Parameters:
- Model: The model that is used to produce the outputs
- Temperature: The temperature of the model being tested
- Max Tokens: The maximum number of tokens the model being tested can output
- System Prompt: The system prompt to be passed to the model being tested
Running by uploading custom Question/Answer CSV
If you have the outputs from your model collected already, and just want to run the tests against them, you can do so by choosing the “Upload CSV” option.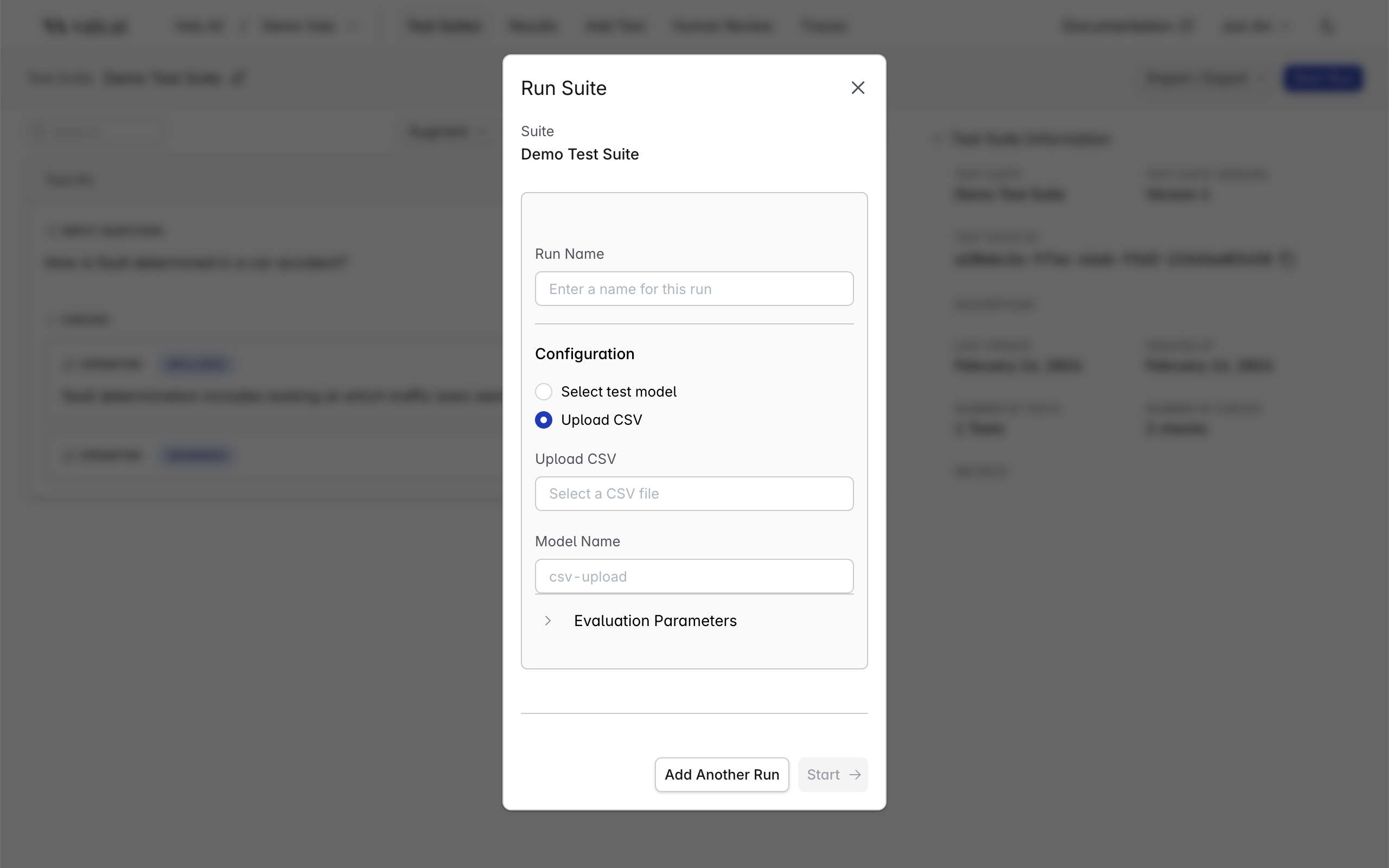
CSV Format
The CSV should contain the questions and your model’s corresponding outputs. OnlyQuestion and Answer are required. Any additional columns will be treated as context key-value pairs (the column name becomes the key, each cell becomes the value).
📎 View Example
Vals will match each row against your suite’s tests and run the defined checks against the uploaded outputs. You can also specify a model name to record which model produced the outputs.
Parameters
There are a few parameters that you can set to control how the run works.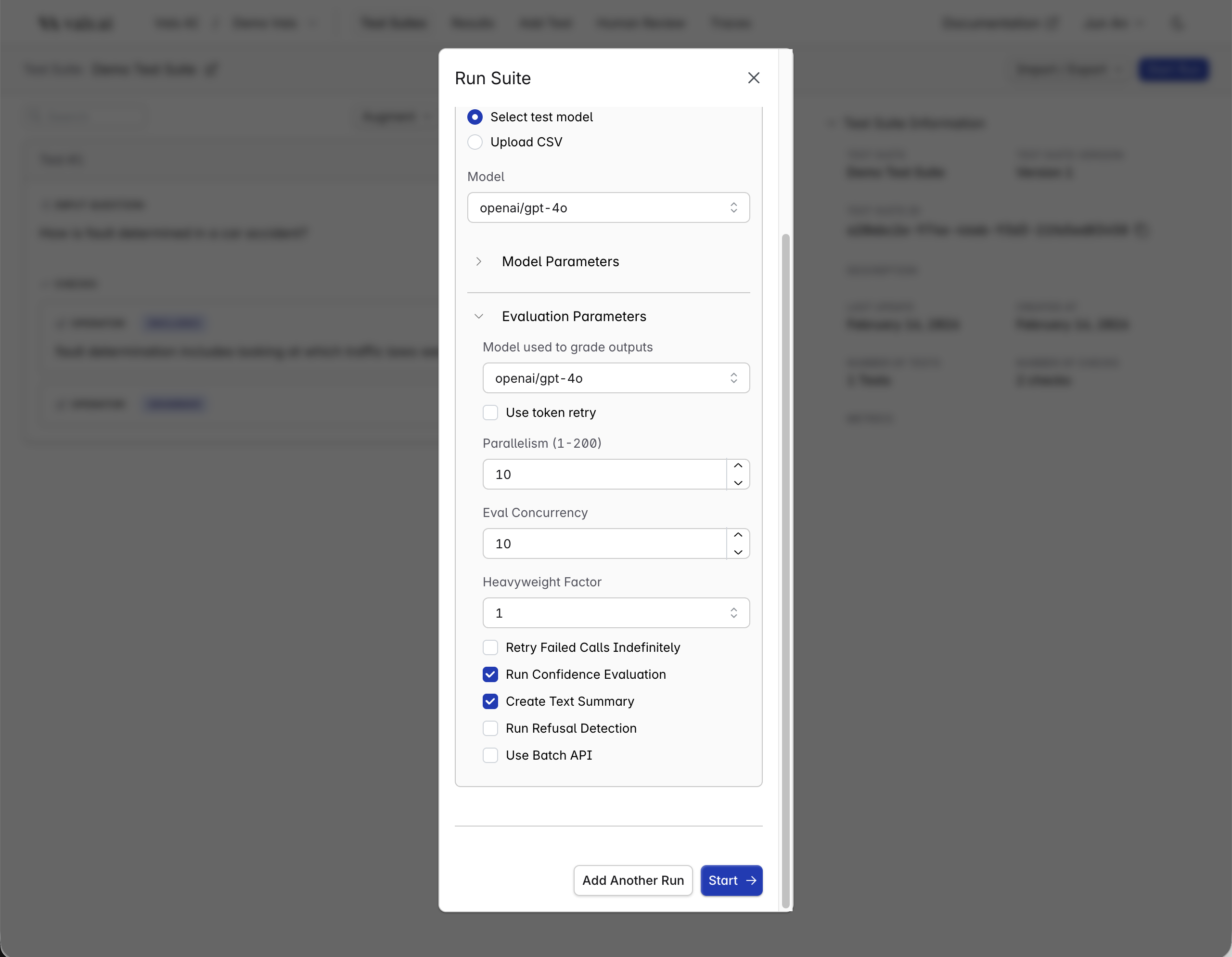
- Evaluation Model: Our evaluation suites use LLMs behind the scenes for checks like includes. The evaluation model you select from this dropdown will grade the outputs of the testing model.
- Parallelism: This controls how many tests are running at any run time. Set it to a higher number to make the run finish faster. Set it to a lower number depending on rate limits.
- Eval Concurrency: Controls how many checks are evaluated in parallel. Defaults to the same value as Parallelism.
- Heavyweight Factor: Runs each check multiple times to reduce variance in the results. For example, if it was set to 5, each check would be run 5 times, and the final result would be the mode.
- Retry Failed Calls Indefinitely: Retry model calls until they succeed.
- Run Confidence Evaluation
DEFAULT: Compute and display a confidence score (high or low) for each check. - Create Text Summary
DEFAULT: Create summary of the run. - Run Right Answer Comparison
DEFAULT: Run right answer comparison. - Run Refusal Detection: Compute and display refusal rate (model refused to respond).
- Use Batch API: Use (if supported) the provider’s batch API to run model calls.