Operators
We have support for a variety of operators, described briefly below. Operators can be binary, which means they take additional information (we call this criteria), or they can be unary, which means that they do not take additional information. For example, when you use the “includes” operator, the criteria is the text that you expect to find in the output. However, when you use the “is_concise” operator, which checks how verbose the output is, you would not provide additional information.Semantic Operators
includes: Determines whether the LLM output mentioned a specified term or phrase, based on its semantic meaning.
satisfies_statement: Check if the LLM output satisfies the criteria
answers (unary): Checks that the output answers the question provided in the test input. For instance, if the prompt question is How does one gain US Citizenship? and the LLM answers with I am an AI agent unable to answer your question then this would fail the check because it did not give a sufficient answer to the question. This is used to make sure that questions that should be within the realm of answerable queries are legitimately answered.
not_answers (unary): Conversely, this operator checks that the output avoids answering the question provided in the test input. For instance, if the prompt question is Can you tell me a joke? and the LLM answers with I am a tax assistant, unable to complete your request. then this would pass the check. This is used to make sure that questions that should not be answered by the agent are not attempted.
excludes: Determines whether the LLM output mentioned a specified term or phrase, based on its semantic meaning.
equals: Determines whether the LLM output has semantic equivalency to a specified term or phrase.
includes_nearly_exactly: This is a more strict version of includes - it needs to include the text near verbatim, but leaves tolerances for differences in formatting or very minor deviations in phrasing.
affirmative_answer (unary): If the prompt is a Yes / No question, this operator checks if the output answers affirmatively. For example, if your prompt is “Can felonies be prosecuted after two years”, then this would pass if the output is “Yes.” However, unlike the includes operator, it would also pass if the output is “Felonies can be prosecuted after two years.”
negative_answer (unary): This is the inverse of an affirmative answer.
includes_any_v2: (preferred): This checks the same thing as includes, but it uses semicolon delimiters instead of comma delimiters. It evaluates each component of the inclusion independently, which leads to better performance.
String Matching Operators
equals_exactly: Determines whether the output matches the words provided, in their exact form.
includes_exactly: Determines whether the output includes the words provided, in their exact form.
regex: Evaluates an arbitrary regex pattern against a given input string.
excludes_exactly: Determines whether the output excludes the words provided, in their exact form.
Constitutional Operators
is_not_hallucinating (unary): Ensures that any entities found within the output can also be found verbatim via a Google search. This is especially useful for legal cases: for example, if the LLM mentions “Jeffords v. NY Police Department”, the LLM will determine if this case exists.
no_legal_advice (unary): This is a constitutional check that determines if the LLM explicitly gives legal advice.
is_safe (unary): Checks that it does not contain content of one of the following categories: hate, harassment, self-harm, sexual content, or violence.
is_concise (unary): Ensures that the output is concise.
is_coherent (unary): This determines if the output logically flows together and makes sense within the context of the prompt.
progresses_conversation (unary): Ensures the output moves the conversation forward.
grammar (unary): Ensures the output is grammatically correct.
is_polite (unary): Ensures the output does not contain any impolite language.
Formatting Operators
list_format (unary): Ensures the output is formatted as a list or other enumeration.
valid_json (unary): Ensures that the output is JSON-parseable.
less_than_length: Ensures that the output is under a given number of characters.
valid_yaml (unary): Ensures that the output is YAML parseable.
Consistent With Source Operators
consistent_with_context (unary): If the “Context” feature is used, this ensures that the LLM output does not contradict the information within the context provided.
consistent_with_docs (unary): If any files are uploaded, this ensures that the LLM output does not contradict information contained with the files.
Example Operator Usage
You can see example checks for every operator by navigating to the test suites page, clicking “Import Quick Start Test Suite”, then choosing Suite Family: “Basic Examples” and “operator_examples”.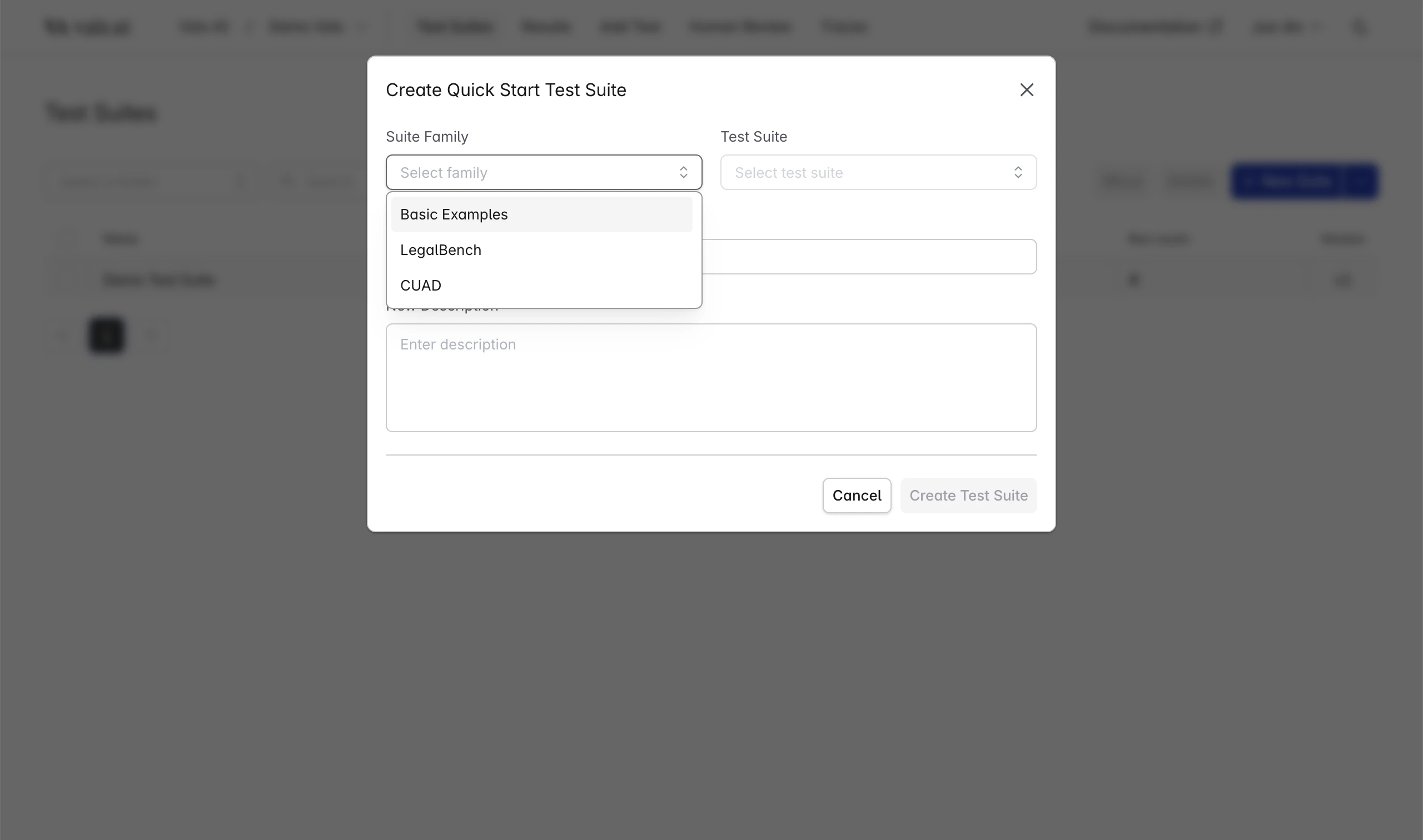
Custom Operators
We also provide the option for users to create their own custom operators. This is useful for when you want more flexibility behind the prompts you are evaluating checks with. These operators can be accessed from within the setting page where you can then create one which will be only available from the project in which it was created from. Here is an example of what it would look like to create an operator from within the platform: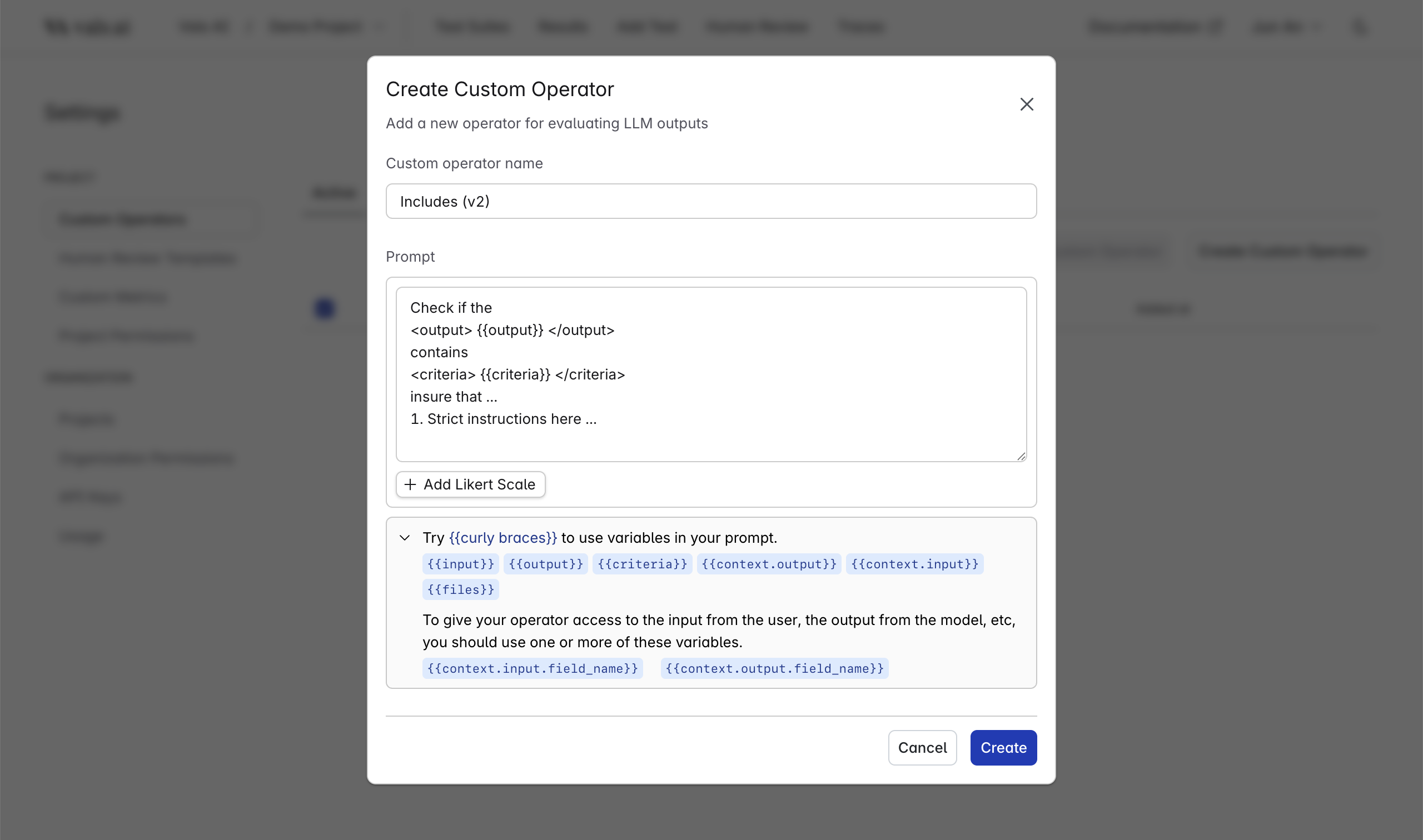
Be specific, as the model will only know what you provide it inside of the prompt.We have a limited amount of variables that you can pass into your prompt.
Variables
| Variable | Description |
|---|---|
{{input}} | The input provided to the LLM under test. Usually contains a question or statement you want the model to respond to |
{{output}} | The output from the model that was returned after responding to the input |
{{criteria}} | The criteria from the check that is defined from within a test |
{{context.input}} | The input context that is defined from within the test that is shared between all checks |
{{context.output}} | The output context contains additional information about the model such as its reasoning |
{{files}} | All the files that were added to the test passed into the prompt defined by the user |
Context Variables
You can pass in context to your prompt by accessing the value such as{{context.input.date}} or {{context.output.user_email}}.
These fields come from the context that you define inside of the test. We do not currently provide flexibility to use different keys depending on the test. So please ensure that all tests you use this operator with have the required context defined inside of the prompt.
Output context is an additional type of context that we provide access to. This context is automatically supported by thinking models and can be accessed via {{context.output.reasoning}}.
If you want to use any other output context, you can define it inside of the question answer pair csv when you import as described here.
Files
When passing in the files we will convert the respective documents into chunks. If the context window of the model is too small for the text, we will shorten the documents automatically. You can access the chunks of the files by accessing{{files}} in your prompt. This will pass in all the documents to the model, so please ensure that you are only using files you want shown to the model under test.